Products
Products Overview
Make confident insights-driven decisions
DeepSights™
Bring trusted insights into daily work effortlessly
DeepSights™ WorkSpace
Manage your insights strategy from one place
DeepSights™ API
Unlock market insights value
Solutions
By role
C-Level
Insights & analytics managers
Marketing professionals
Use cases
By industry
Consumer goods
Financial services
Healthcare & pharma
Retail
Customers
Company
col
About Us
Partners
Contact us
Careers
Why Market Logic?
News
Resources
Resource Hub
Blog
Thought Leadership
Case Studies
Webinars & Events
Product Videos
Request a demo
Industry
Type
Search by keyword
Webinars & virtual events
Sep, 2023
Insights leaders from Philips and Market Logic software share their first-hand account of what generative AI for insights looks like when deployed within an enterprise insights
Read more
Editors Picks
Jul, 2024
Event Brief: Watch the Demo Days for Research & Analytics Tools to: Join hundreds of researchers, designers, consultants, product managers and insights
Industry event
Jan, 2024
Join Market Logic software to see a first-hand account of what generative-AI looks like when deployed within a healthcare technology market research and insights
MLS event
May, 2024
Join Market Logic and MMR Research to see a first-hand account of what generative-AI for insights looks like when deployed for research and insight’s function. This
F2F Events
Jun, 2024
Market Logic participated in the premiere Digital Marketing World Forum in London, UK on June 25-26, 2024. This conference offered an exciting opportunity to explore the future of
Apr, 2024
Market Logic is excited to be participating in ESOMAR's upcoming AI Tools Series to share the latest innovations in DeepSights, as well as a live Q&A with other leading
Market Logic joins thought leaders from Estée Lauder, Kerry, Fuel Cycle and FGX for a panel discussion on the evolution of the insights function in today's AI-driven
Mar, 2024
Join Market Logic and partners as we deep dive into how AI is being applied in the consumer insights space to drive innovation and informed decision making. This event will
Feb, 2024
Market Logic spoke alongside MMR at Europe's leading qualitative research summit in Berlin. Stream the presentation
Oct, 2023
In this session we'll share best practices for intelligent research management in the healthcare and pharmaceutical industries. Learn how you can support flexible workflows,
Are you an insights and intelligence professional? Now's your chance to learn first-hand how Market Logic can bring your market insights to life in our four-part webinar
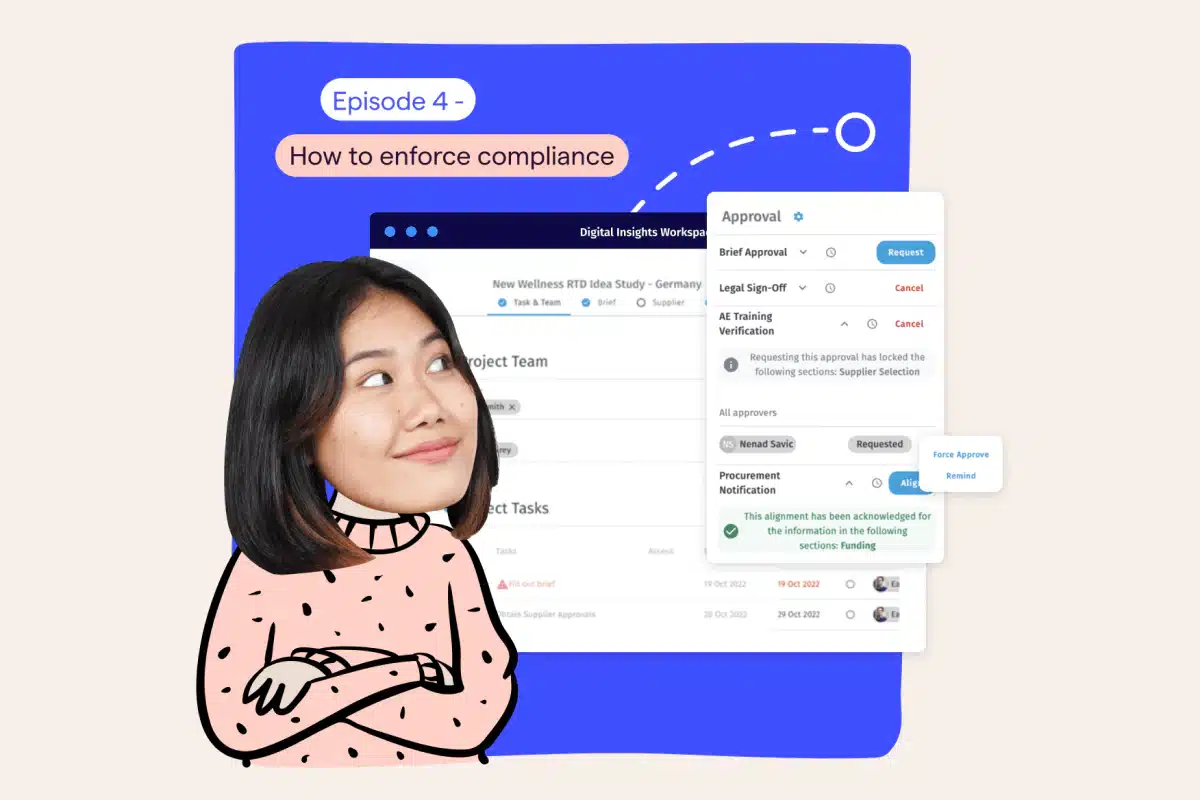
Enforce and monitor compliance in automated market research
Keep up to date with the latest insights from Market Logic as well as all our company news in our free monthly newsletter.
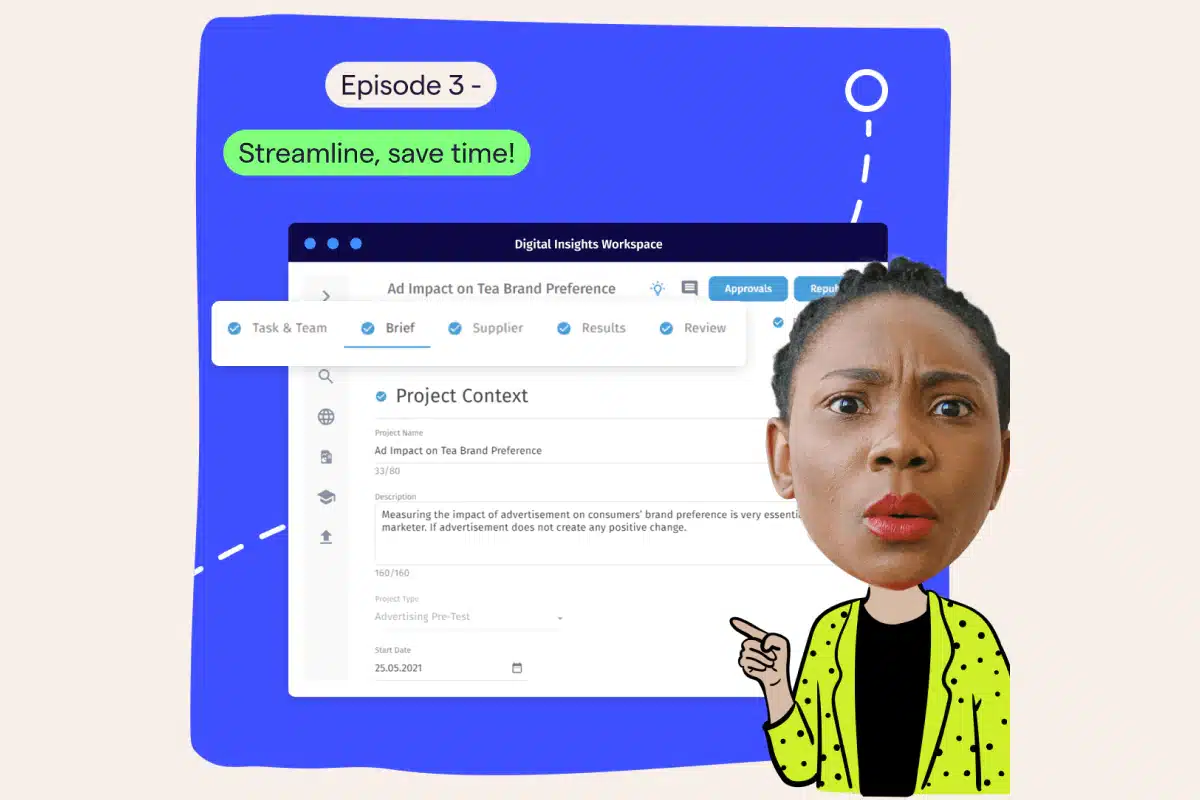
Save time streamlining and automating your market research
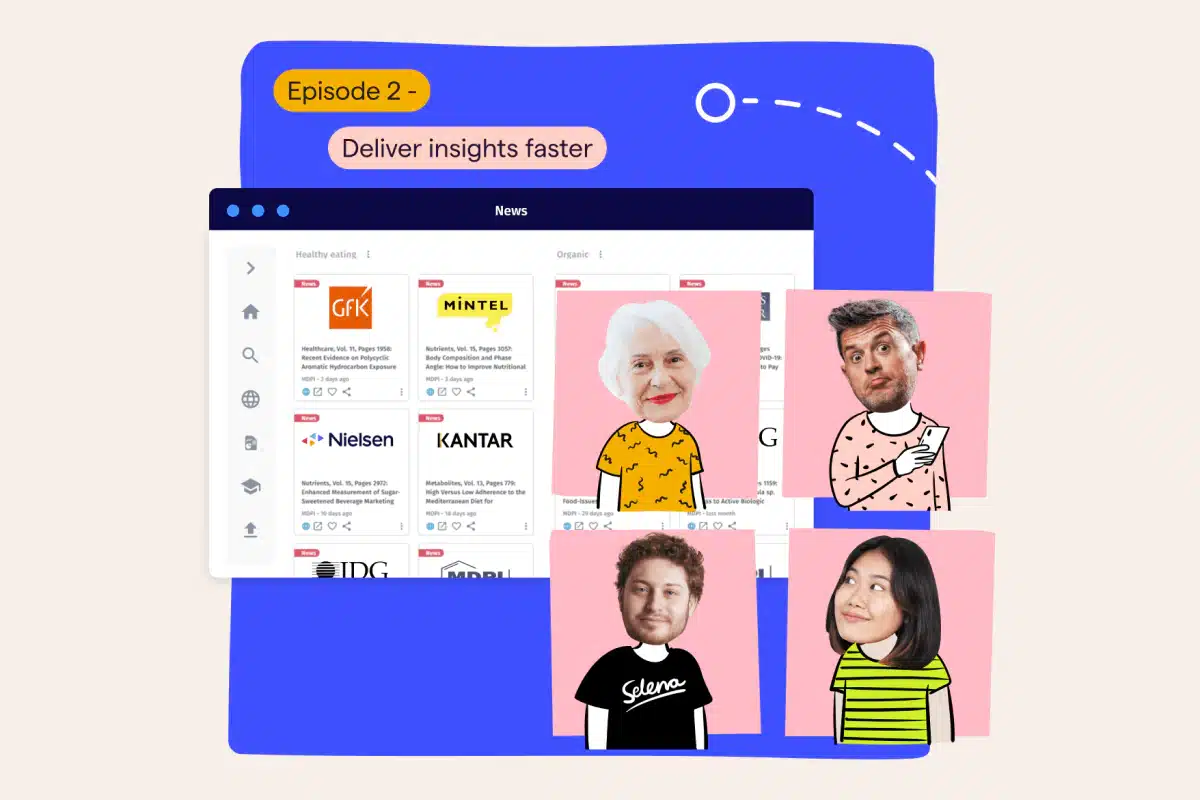
Cut through the noise and deliver faced-paced market and competitive intelligence at
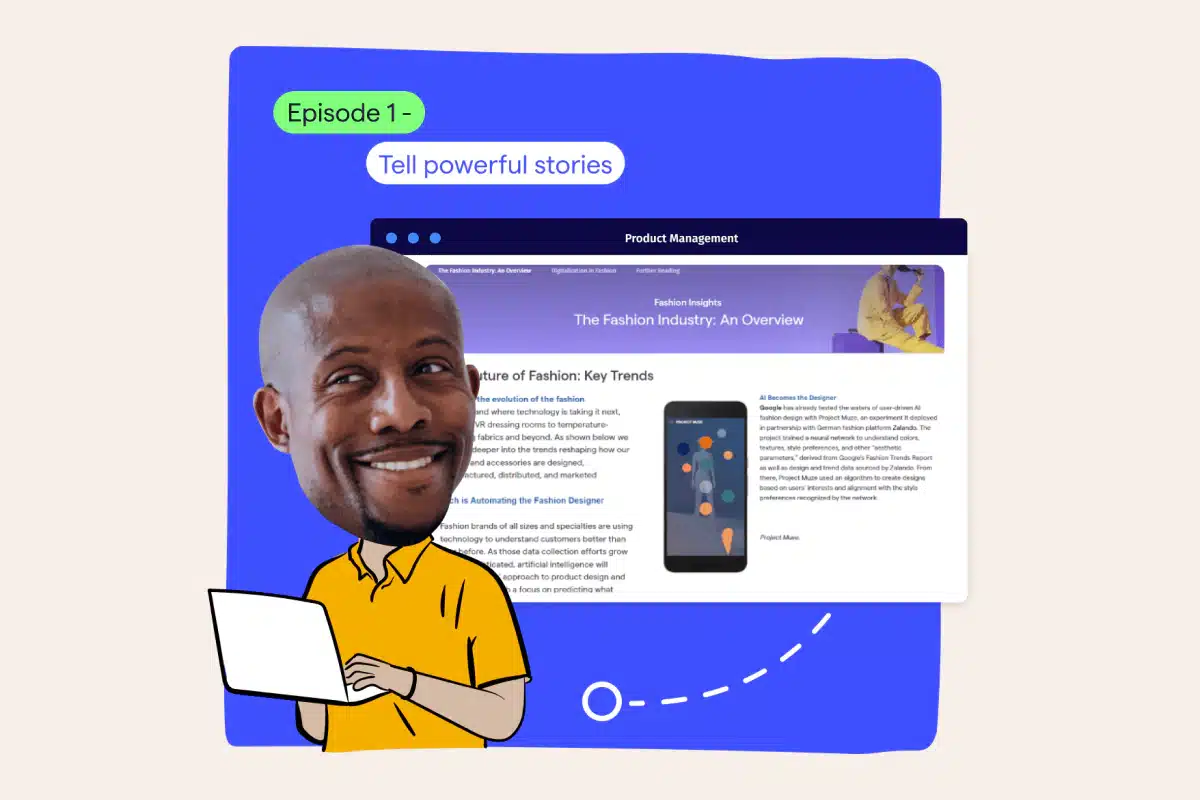
Tell powerful stories - Say goodbye to information overload and biased cherry-picking! With our cutting-edge insights storytelling tools tailored to insights experts, you can
Jul, 2023
In this tech showcase, you’ll hear from our Senior Director for Experience & Design Christian Bobzin on the development of this product and the newest integrations that are
1 2 3 4





























![[Panel Discussion] From Support Staff to Pivotal Partner: Advancing the Role of Insights](https://marketlogicsoftware.com/wp-content/uploads/2024/04/informaconnect-presents.webp)